一、破解百度云的网页大文件下载限制
百度云网页下载大文件会让你打开客服端下载,网页不提供下载链接,以前有一个“一行js代码破解百度云大文件下载限制”的方法,有大佬还用这个BUG做了Chrome浏览器的插件,但是百度云更新后就将该BUG修复了,所以现在这个方法用不了了,插件也就用不了了。
我们就只能用最原始的方法也是最好用的方法来获取它大文件的下载链接。
首先打开网页百度云,然后登陆进去
然后按F12打开开发者工具,然后选中里面的Network,然后选择它下面的All

然后按F5刷新界面,你就会看见下面的Network里面多了很多东西比如ajax请求等等,当加载到如下图中那个js时应该就加载完了
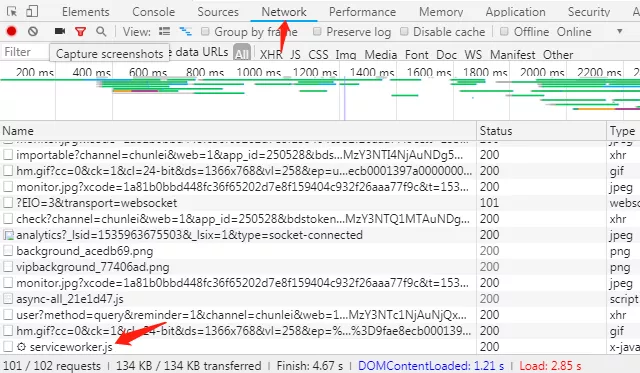
然后不要关开发者界面,在上面的网页中点击下载你要下载的资源

然后你就会发现Network里面又刷新了几个ajax,然后找到下图中download开头的那个ajax请求
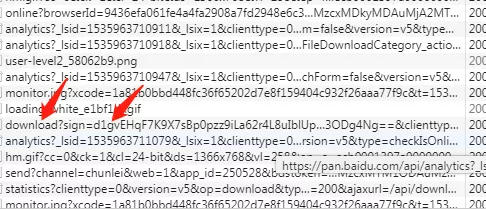
然后点击它,右边就有他返回的数据,展开就能看到一个dlink,dlink里的链接就是我们的文件下载链接

最后将链接复制到浏览器地址窗口或者迅雷里面就可以下载了
二、百度云下载限速破解
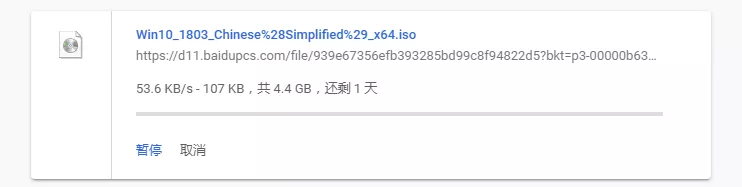
这个方法的原文章链接我找不见了,只有代码还在,先说一下代码的原理,首先在链接的头里面分析该资源的大小,然后将大小分割成线程块(开多少个多线程就分割成多少个块),然后将每个线程里分到的块写到该块的指定位置。首先python的多线程有GIL,所以我测试的时候10M大小的文件100个线程速度最快,下面是我测试的结果,你可以将上面获取到的链接放进来就可以下载了。
这是测试资源在浏览器以及客服端的下载速度

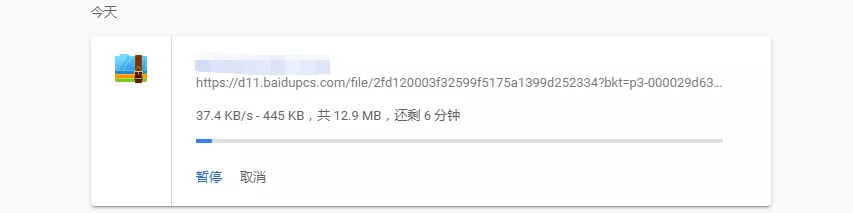
然后这是该程序下载的速度(相同的资源)

对下载下来的文件MD5对比
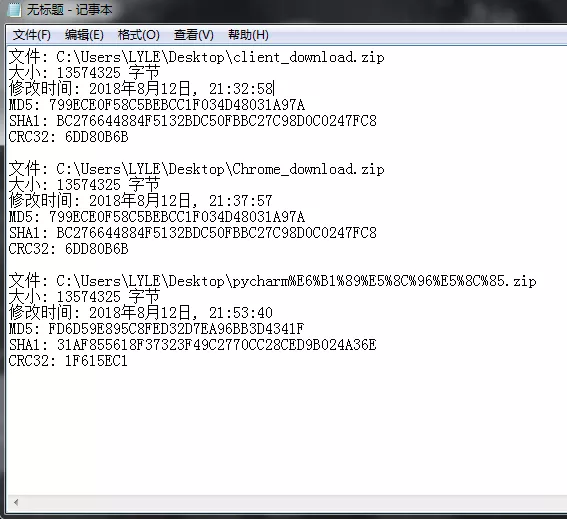
前两个是浏览器和客服端下载的,最后一个是该程序下载的,为啥不一样呢,前两个都是将资源直接下载下来,而该程序是分析链接头然后根据文件的名字新建一个文件,然后在往里面写入数据,当然MD5就不一样啦。但是三个文件打开,里面的资源没有一点问题,都能正常打开使用。
源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
| import sys
import os
import win32api
import time
import multiprocessing
from multiprocessing import Process
from tqdm import tqdm
import tkinter
import tkinter.messagebox
import requests
import re
import threading
j = 0
url = "下载链接填在这里"
head = requests.head(url)
size = int(head.headers["Content-Length"])
filename = head.headers["Content-Disposition"]
print(head.headers)
n = 100
spos = []
fpos = []
persize = int(size/n)
intsize = persize*n
for i in range(0,intsize,persize):
spos.append(i)
fpos.append(i+persize-1)
if persize < intsize:
fpos[n-1] = size
fl = re.compile(r'filename=(.*)', re.S)
filename = fl.findall(filename)
filename = filename[0]
fp = open(filename,"wb")
fp.close()
fp = open(filename,"rb+")
tmp = []
strat_time = time.time()
def readfilesizez(filename):
while True:
downsize = os.path.getsize(filename)
print(downsize)
time.sleep(1)
def downfile(url,spos,fpos,fp):
global j
head = {}
head["Range"] = "bytes=%d-%d" % (spos,fpos)
res = requests.get(url,headers=head)
fp.seek(spos)
fp.write(res.content)
j+=1
print(j)
# t1 = threading.Thread(target=readfilesizez, args=(filename,))
# t1.start()
for i in range(0,n):
t = threading.Thread(target=downfile, args=(url,spos[i],fpos[i],fp))
t.setDaemon(True)
t.start()
tmp.append(t)
for i in tmp:
i.join()
fp.close()
close_time = time.time()
speed = float(size)/(1000.0*(close_time-strat_time))
print("spend time: %0.2f s" % float(close_time-strat_time))
print("finished... average speed: %0.2f KB/s" % speed)
# print(spos)
# print(fpos)
|
